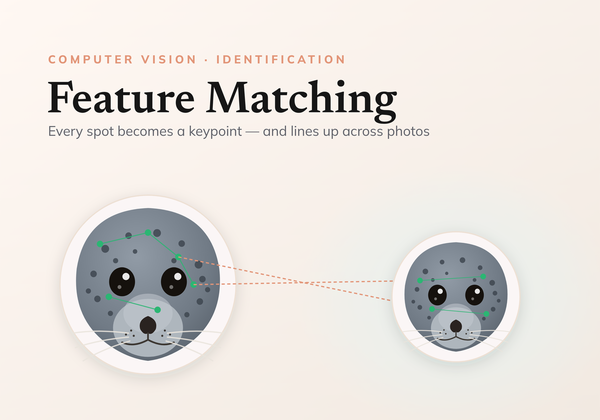
On this page
In this post, we will explore essential preprocessing techniques for normalizing animal images, preparing them for individual identification.
We will focus on the initial stages of the machine learning pipelines developed for various projects, specifically bear and trout identification. In both cases, similar computer vision techniques and strategies were employed to successfully create robust identification systems.

In the bear identification project, the processing stage encompasses bear face detection, head segmentation, and head normalization.
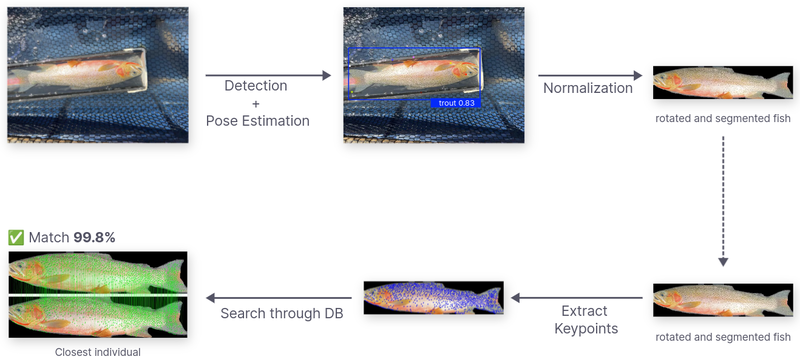
In the trout identification project, the processing stage includes trout detection, pose estimation, and image normalization.
Both projects use similar preprocessing techniques, detailed and illustrated throughout this post.
Segmentation
To identify individuals reliably, we first isolate the animal and strip away the background. This lets the identification model focus only on the signal that matters — the markings — instead of being distracted by surrounding pixels.
In the case of bears, both existing literature and our research indicate that their facial markings and shapes are unique, making them effective for individual identification. Similarly, for trout, individuals can be identified by their distinct and stable spot patterns.
Segmentation 101
Semantic segmentation assigns a class label to each pixel in an image, such as ‘person,’ ‘dog,’ or ‘flower,’ grouping together pixels of the same class. Conversely, instance segmentation distinguishes between individual instances of objects within the same class, treating each one as a separate entity.
 Semantic segmentation vs Instance segmentation
Semantic segmentation vs Instance segmentation
Instance segmentation techniques are generally more effective for isolating individual subjects in images.
GroundingDINO + SAM = Mask Dataset
Generating a segmentation dataset for a diverse array of animals has become straightforward by combining an open-set object detector like GroundingDINO, which localizes and detects animals using text prompts, with a promptable segmentation model such as the Segment Anything Model (SAM).
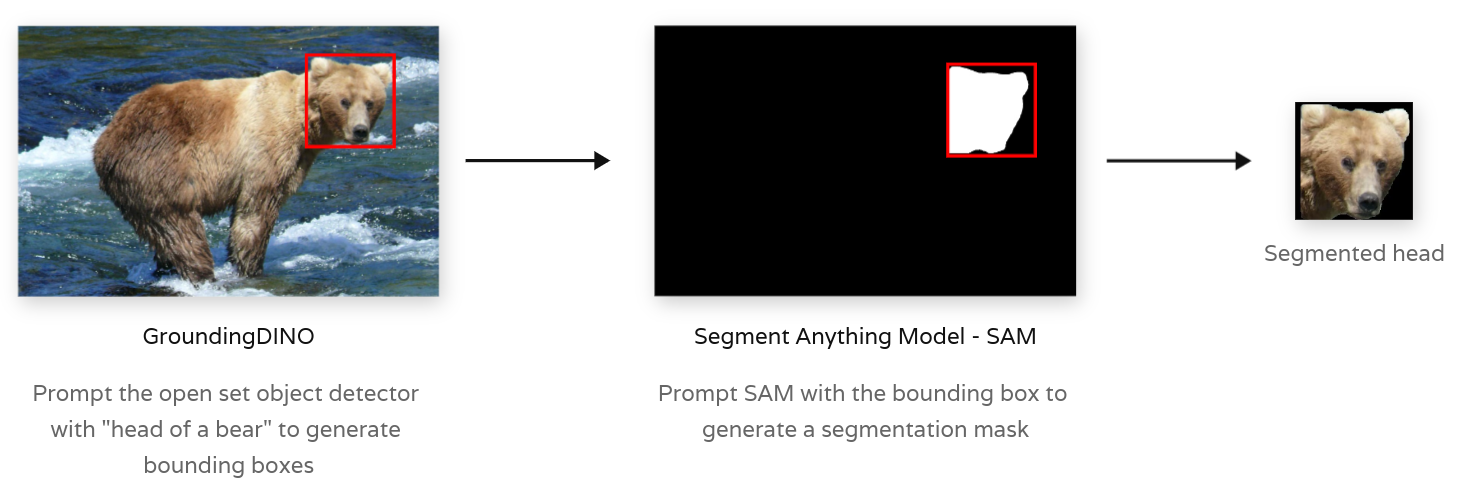 Generating Bear Face Masks combining GroundingDINO and SAM
Generating Bear Face Masks combining GroundingDINO and SAM
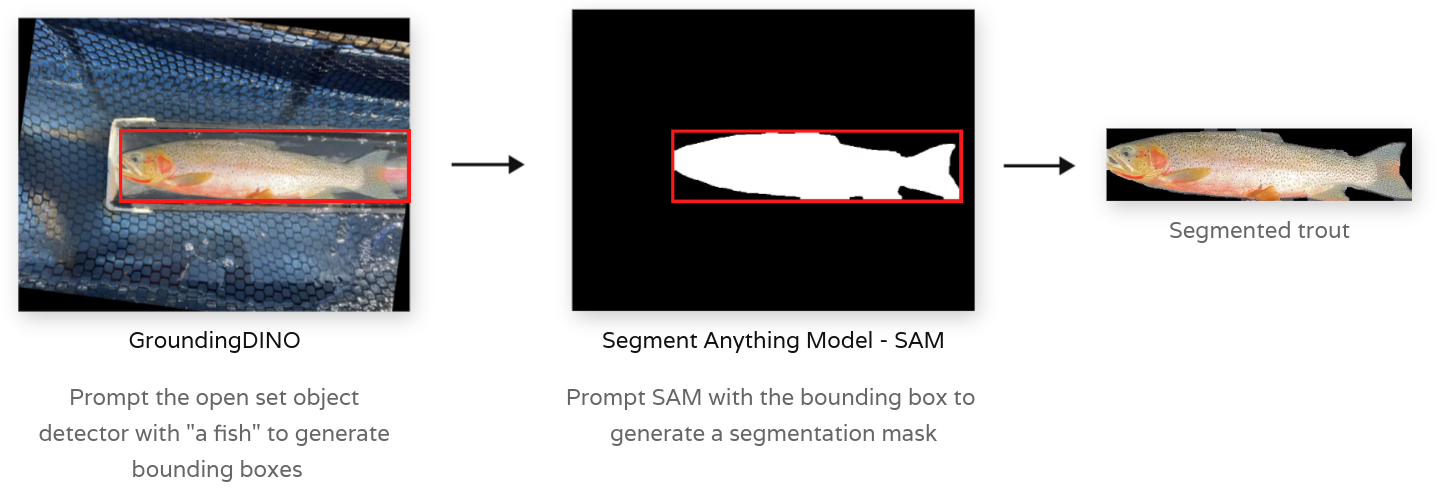 Generating Trout Masks combining GroundingDINO and SAM
Generating Trout Masks combining GroundingDINO and SAM
Both of these computer vision models are large and tend to run slowly on a CPU. Therefore, it is often beneficial to use the generated dataset of masks to train a smaller, faster instance segmentation model capable of localizing and segmenting the animal in a single pass.
GroundingDINO
Segment Anything Model - SAM
The Segment Anything Model (SAM) produces high quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image. It has been trained on a dataset of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.
 SAM Github / SAM output example
SAM Github / SAM output example
Finetune an Instance Segmentation model
Once the dataset of masks is generated using GroundingDINO and SAM, the next step is to train a compact model that can perform both tasks simultaneously and operate efficiently on a CPU. Enter YOLO!
YOLO Overview
YOLO is a fast, accurate, and widely used computer-vision model. It excels at a range of tasks — object detection, tracking, and image classification — and, crucially for us, instance segmentation: it not only identifies and localizes objects but also separates individual instances. It is easy to use and efficient enough for real-time work, which makes it a strong fit for segmenting our animals on a CPU.
 YOLOv8 Computer Vision Tasks
YOLOv8 Computer Vision Tasks
Training
Data Augmentation
We can employ various data augmentation techniques to artificially enhance our training set. These techniques help increase the diversity of the data and improve the model’s robustness.
 The same fish under each augmentation — the model learns to recognize it through all of these variations
The same fish under each augmentation — the model learns to recognize it through all of these variations
Tap each method to see what it does:
Varying the size of the images to simulate different distances from the camera.
Rotating images by a random angle to account for variations in orientation.
Combining multiple images into a single mosaic to create a more complex training example.
Flipping images horizontally or vertically to introduce mirror variations.
Randomly adjusting brightness, contrast, saturation, and hue to simulate different lighting conditions.
Randomly cropping sections of the image to focus on different parts of the animal, helping the model learn features in varied contexts.
Adding random noise so the model is more resilient to variations in input quality.
By applying these augmentation techniques before feeding the images to the model, we can significantly enhance the training dataset, leading to improved model performance and generalization.




Training Results
Typically, training a satisfactory segmentation model requires only a relatively small number of epochs. This allows for efficient model development while still achieving effective performance on the task.
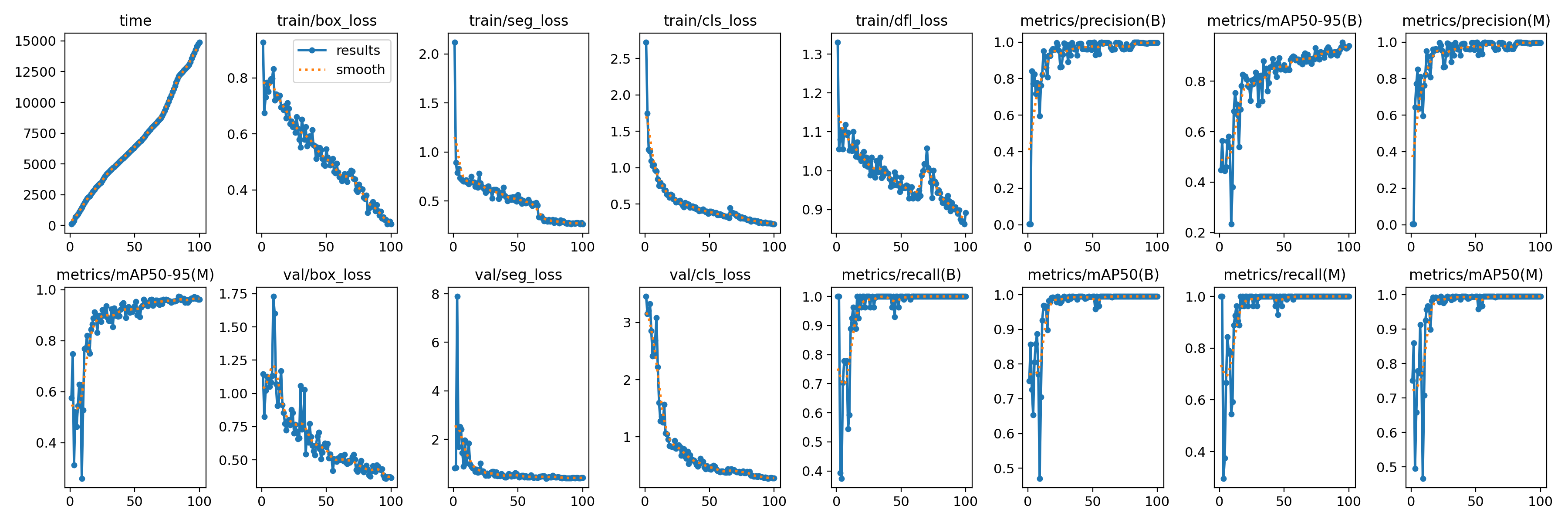 Results of the training of a segmentation model on trouts for 100 epochs
Results of the training of a segmentation model on trouts for 100 epochs
Qualitative Results
A qualitative evaluation of segmentation model was conducted on a random batch from the validation set. The results demonstrate that the model performs with high accuracy, effectively localizing and segmenting out trouts.
| Ground Truth | Prediction |
|---|---|

|

|
Normalization
Producing normalized images for the identification stage is critical. It makes it easier to compare different individuals in a consistent manner and it boosts the model accuracy.
For bears, the head crops must be resized and padded to a fixed size, since the identification model expects fixed-size input. With a segmentation mask in hand this is straightforward: cut out the head and pad the result with black pixels to reach that size.
 Normalized bear faces
Normalized bear faces
For trouts, we want to realign the fish to face the same direction and then apply the segmentation masks to cut out the background too.




Rotation
Images often need to be rotated so they all share a consistent angle. This alignment matters because identification models are sensitive to variations in rotation.
To determine the appropriate rotation angle for consistent alignment, we can leverage a class of machine learning models known as pose estimation models. These models are trained to predict specific anatomical features of the animal, such as the eye, nose, mouth, tail, and other keypoints. By accurately localizing these features, we can calculate the required rotation angle to standardize the orientation of the images.
Pose Estimation 101
 Pose estimation to localize the key points on a human body
Pose estimation to localize the key points on a human body
Pose estimation is the computer-vision task of working out the spatial configuration of a subject in an image or video. It pinpoints key points on the body — joints, facial landmarks — or the orientation of an object. From those detected keypoints, we can normalize images: realigning them into a consistent representation based on the pose.
This capability to accurately identify these keypoints with a machine learning model enables us to realign and normalize images, ensuring that all trout are oriented in the same direction. Additionally, it allows for the detection of the side of the trout that is visible in the image, enhancing our ability to analyze and interpret the data effectively.
 Pose estimation to localize the keypoints of a trout: eye, tail, fins
Pose estimation to localize the keypoints of a trout: eye, tail, fins
To realign the trout images, we utilize the predicted keypoints, particularly the pelvic and anal fins, to determine the appropriate rotation angle needed for horizontal alignment. By calculating this angle based on the positions of these keypoints, we can effectively adjust the orientation of the image, ensuring that the trout is consistently aligned for analysis.
The green line in the images below, drawn between the pelvic and anal fins, serves as a reference point for rotating the image. This line acts as an anchor, allowing us to accurately adjust the orientation of the trout for consistent alignment.
| Original | Keypoints | Rotated | Final |
|---|---|---|---|

|

|

|

|

|

|

|

|

|

|

|

|
Finetuning a Pose Estimation model
By utilizing a pretrained model designed for human pose estimation, we can apply transfer learning techniques to adapt the model for localizing specific keypoints on trout, such as the eye, pelvic fin, dorsal fin, tail, and others.
We can annotate a small dataset with the identified keypoints that we want the pose estimation model to learn. For the trout identification project, a few hundred annotated images proved sufficient to train a highly accurate model. The annotation process is typically conducted in stages, where an initial model can bootstrap the expansion of the annotated dataset, allowing for iterative improvements and enhanced performance over time.
Data Augmentation




Training Results
Typically, only a limited number of epochs are required to train a satisfactory initial pose estimation model. This foundational model can then be further enhanced by incorporating additional data points into the annotated dataset, allowing for continuous improvement in accuracy and performance.
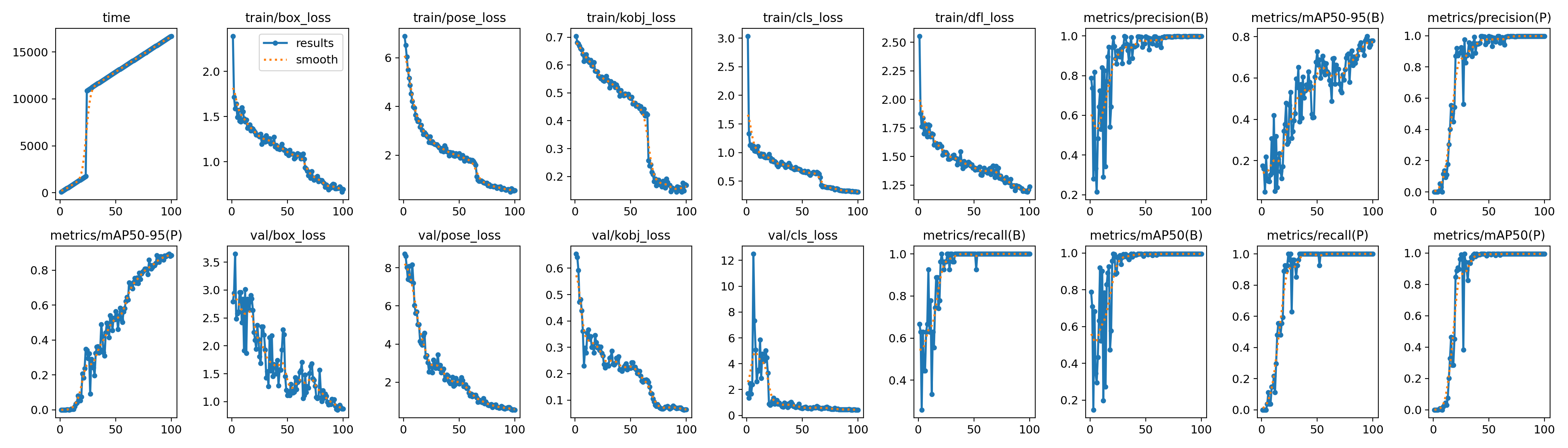 Results of the training of a pose estimation model for trout keypoints localization for 100 epochs
Results of the training of a pose estimation model for trout keypoints localization for 100 epochs
Qualitative Results
A qualitative evaluation of the pose estimation model was conducted on a random batch from the validation set. The results demonstrate that the model performs with high accuracy, effectively identifying and localizing keypoints on the trout.
| Ground Truth | Prediction |
|---|---|

|

|
Conclusion
In this article, we have explored various standard computer vision techniques that often complement each other effectively. An open-set object detector, such as GroundingDINO, combined with a promptable segmentation model like SAM, can facilitate the curation of a training mask dataset. If necessary, a smaller segmentation model designed for real-time performance and capable of running on CPU, such as YOLO, can be trained on this generated dataset.
Normalizing and standardizing the dataset used for downstream identification models is crucial. This can be achieved through various methods, including training a pose estimation model to realign images based on specific keypoints.
These techniques are versatile and applicable to a wide range of problems, making them essential tools in the modern computer vision toolkit.
See these techniques in action
These preprocessing steps feed our real identification systems — explore the full projects they power.